thx-cron¶
L’applicazione permette di creare, schedulare e gestire JOB, che saranno eseguiti in maniera asincrona rispetto all’applicazione principale: l’esecuzione di ogni singolo job può essere periodica o una tantum. Tramite l’interfaccia di admin, l’amministratore di sistema può creare e modificare i jobs, e visualizzare l’esito delle singole esecuzioni.
Ricerca e avvio dei jobs da eseguire sono effettuate tramite il comando django run_jobs che è stato implementato all’interno dell’applicazione thx-cron.
Installazione¶
Installare nell’enviroment thx-cron:
pip install thx-cron
Aggiungere l’applicazione thx-cron nella sezione install_requires del file setup.py
install_requires=[
....
'thx-cron',
....
]
Aggiungere l’applicazione thx.cron nella sezione INSTALLED_APPS del file web/settings/base.py
Importante
thx.cron deve essere importata prima di tutte le apps del progetto (o comunque prima di tutte le apps che conterranno dei jobs da eseguire tramite l’applicazione).
INSTALLED_APPS = [
'thx.cron',
...
]
Definire i parametri di log della nuova app nella sezione LOGGING
LOGGING = {
...,
'handlers': {
...,
'cron': {
'class':'logging.FileHandler',
'formatter':'verbose',
'filename':'/var/log/django/[MY_LOG_NAME]-cron.log',
'level':'INFO',
},
...
},
'loggers': {
...,
'cron':{
'handlers':['cron'],
'level':'INFO',
}
...
Le API non sono ancora complete, ma una volta pronte saranno da importare in questo modo
url(r'^api/cron/', include('thx.cron.api.version1.urls', namespace='api_cron'))
Applicare le migrazioni previste dalla app thx-cron
dj migrate cron
Creazione dei jobs¶
Ogni job che necessita di essere implementato all’interno del progetto deve essere una classe che estende la classe JobHandler e ne ridefinisce il metodo do(). Tale metodo deve contenere il codice che dovrà essere eseguito durante l’esecuzione del job.
Per fare in modo che i jobs delle singole apps vengano individuati e gestiti in modo automatico da thx-cron è necessario che la definizione della classe del job sia inserita all’interno del file jobs.py presente in ogni applicazione.
Questa la classe da ereditare
class JobHandler:
def __init__(self, instance, **kwargs):
self.parameters = kwargs
self.instance = instance
self.logger = logging.getLogger('cron')
self.logger.info("***************************************")
self.logger.info('LOG' + " " + self.instance.name + " id: " + str(self.instance.pk))
self.logger.info('RECEIVED PARAMETERS' + str(self.parameters))
self.logger.info("***************************************")
self.elaboration_time = None
self.elaboration_results = None
self.is_valid = None
self.extra_info = None
self.log_file_content = None
def do(self):
self.elaboration_time = self.get_elaboration_time()
self.elaboration_results = self.get_elaboration_results()
self.is_valid = self.get_if_valid()
def get_elaboration_time(self):
raise NotImplementedError('`get_elaboration_time()` must be implemented.')
def get_elaboration_results(self):
raise NotImplementedError('`get_elaboration_results()` must be implemented.')
def get_if_valid(self):
raise NotImplementedError('`get_if_valid()` must be implemented.')
Importante
solitamente i job chiamano dei classmethod o dei method di modelli evitando di duplicare il codice
vengono utilizzati i job per poter controllare l’esecuzione tramite interfaccia o per operazioni che richiedono del tempo e devono essere eseguite in maniera asincrona
alla creazione di un job è buona norma implementare anche un Command che richiama lo stesso classmethod del job per avere la possibilità di eseguire il job sia da app thx-cron che da shell/crontab
Esempi di files jobs.py¶
Un esempio di job potrebbe essere uno script di importazione:
from thx.cron.utils import JobHandler
from apps.account.imports import ImportDB
class ImportTicketApp(JobHandler):
def import_tables(self):
idb = ImportDB()
idb.start(**self.parameters)
def do(self):
start = timezone.now()
try:
self.import_tables()
self.elaboration_results = json.dumps({"success": "Ticket APP successfully updated"})
self.is_valid = True
except Exception as e:
self.elaboration_results = json.dumps({"error": str(e)})
self.is_valid = False
end = timezone.now()
self.elaboration_time = end - start
return self
Un altro esempio potrebbe essere l’invio di email programmate:
from thx.cron.utils import JobHandler
from apps.organization.models import Employee
class SendEmailError(JobHandler):
def do(self):
start = timezone.now()
try:
msg = Employee.send_email_error_transits(**self.parameters)
self.elaboration_results = json.dumps(msg)
self.is_valid = True
except Exception as e:
self.elaboration_results = json.dumps({"error": str(e)})
self.is_valid = False
end = timezone.now()
self.elaboration_time = end - start
return self
Un altro esempio ancora potrebbe essere l’esportazione di dati (operazione che potrebbe richiedere del tempo per essere eseguita). In questo esempio, per ogni esecuzione del job, vengono salvate all’interno del JobLog anche delle informazioni aggiuntive (extra_info) e il contenuto di un file di log (log_file_content), entrambi relativi alla singola esecuzione.
from thx.cron.utils import JobHandler
from from apps.document.utils import ExportXMLDocumentUtils
logger = logging.getLogger('xml_export')
class ExportDocumentXML(JobHandler):
def __init__(self, instance, **kwargs):
super().__init__(instance, **kwargs)
self.ddt_id = self.parameters.get("ddt_id", None)
self.recipient_list = self.parameters.get("recipient_list", None)
if not isinstance(self.ddt_id, int):
raise ValueError(_("ddt_id must be defined and integer"))
def do(self):
start = timezone.now()
try:
self.extra_info = {}
msg, extra_data = self.create_and_send_xml_document()
self.elaboration_results = json.dumps(msg)
for index, data in enumerate(extra_data):
self.extra_info[index] = data
self.is_valid = True
except Exception as e:
self.elaboration_results = json.dumps({'error': str(e)})
self.is_valid = False
end = timezone.now()
self.elaboration_time = end - start
with open(logger.handlers[0].baseFilename, 'r') as f:
self.log_file_content = f.read()
return self
def create_and_send_xml_document(self):
export_and_send = ExportXMLDocumentUtils()
message_result, extra_data = export_and_send.do(**self.parameters)
return message_result, extra_data
Configurazione dei job¶
Le configurazioni dei job che devono essere eseguiti dal comando run_jobs, è memorizzata nel database dell’applicazione all’interno del modello Job. All’interno di questo modello vi sono diversi campi: alcuni sono informazioni generali del job, altri fanno riferimeto ai dati di schedulazione.
Informazioni generali
Le informazioni generali di un job comprendono:
- status
indica lo stato del job e puo” assumere 4 valori: DRAFT, TO RUN, RUNNING, COMPLETED
- name
campo di testo contenente il nome del job
- command
campo di testo contenente l’indicazione della classe che definisce il job (es. “apps.account.ImportTicketApp”)
- parameters
contiene i parametri necessari al job durante l’esecuzione. I parametri sono indicati in formato JSON e devono essere per nome e tipologia compatibili con quanto indicato nella classe che definisce il job.
Dati di schedulazione:
La configurazione della schedulazione comprende i seguenti campi:
- year
anno di shedulazione (numero intero)
- month
mese di shedulazione (numero intero compreso fra 1 e 12)
- day
giorno di shedulazione (numero intero)
- hour
ora di shedulazione (numero intero compreso fra 0 e 23)
- minute
minuto di shedulazione (numero intero compreso fra 0 e 59)
- weekday
giorno della settimana di shedulazione (numero intero compreso fra 0 e 6)
- is_una_tantum
indica se il job è ripetitivo o una tantum (booleano)
In base a questi parametri i job si dividono in due macrocategorie: non ripetibili (una tantum) e ripetibili.
Importante
Impostando il campo is_una_tantum a True oppure valorizzando tutti i campi di schedulazione (ad eccezione del campo weekday), si ottengono jobs non ripetitivi che verranno messi in COMPLETED al termine della esecuzione
Lasciando vuoti tutti i campi sopra indicati il job verrà eseguito ad ogni esecuzione di run_jobs e al termine della esecuzione verrà rimesso in stato TO RUN.
Lasciando blank alcuni dei campi di schedulazione, è possibile configurare i job in modo da applicare una ripetività ai job
Ad ogni esecuzione del command run_jobs, vengono individuati tutti i job con stato TO_RUN. Per ognuno di essi viene analizzata la configurazione di schedulazione: se il job viene dichiarato eseguibile, il suo stato verrà reimpostato a RUNNING, il job verrà eseguito e al termine della esecuzione lo stato sarà modificato in TO RUN (per i job ripetibili) oppure COMPLETED (per i job una tantum).
Di seguito alcuni esempi di configurazione di shedulazione:
ESEMPIO DI COMPILAZIONE 1
• year: 2020
• month
• day: 3
• hour: 12
• minute:00
IL JOB VIENE ESEGUITO PER IL SOLO 2020 TUTTI I 3 DEL MESE ALLE ORE 12
ESEMPIO DI COMPILAZIONE 2
• year:
• month: 2
• day: 3
• hour: 9
• minute: 00
IL JOB VIENE ESEGUITO TUTTI GLI ANNI SOLO IL GIORNO 3 FEBBRAIO ALLE 9
Il Job log¶
I dati relativi alla singola esecuzione del job sono memorizzati nel database dell’applicazione all’interno del modello JobLog.
Questo modello contiene le seguenti informazioni:
- job
job di riferimento
- elaboration_time
tempo di elaborazione della singola esecuzione
- elaboration_results
risultato dell’elaborazione. I dati devono essere memorizzati in formato JSON.
- is_valid
flag che indica se l’esecuzione è andata a buon fine o fallita (booleano)
- extra_info
informazioni aggiuntive relative alla singola esecuzione. I dati devono essere memorizzati in formato JSON.
- log_file_content
campo di testo in cui memorizzare il contenuto di un file di log relativo alla alla singola esecuzione.
Configurazione crontab linux¶
Il comando run_jobs deve essere schedulato all’interno del crontab della macchina
# Esempio senza docker
15 11 * * 7 root /home/www/www.acomea.it/bin/django run_jobs
# Esempio con docker
*/10 * * * * root cd /home/docker/opencapital-2020 && docker-compose exec -d django python manage.py run_jobs
Interfaccia di admin¶
Portandosi nel pannello amministrativo del nostro progetto e selezionando la il menu Cron (1), sarà possibile creare ed impostare i job per cui è stata implementata la logica.
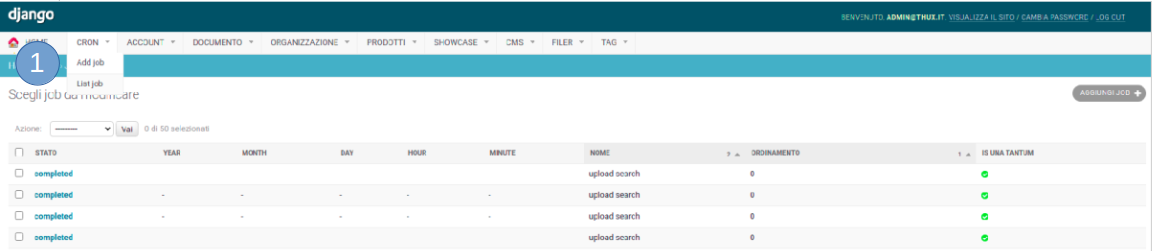
Nello specifico, per ogni Job sarà possibile:
selezionare dalla tendina Command il job che si vuole eseguire (nella tendina saranno presenti tutti i job individuati nei vari file jobs.py delle applicazioni del progetto)
indicare quali parametri saranno utilizzati durante l’esecuzione del job attraverso la textbox “Parameters” (i parametri devono essere inseriti nel formato JSON, e devono essere per nome e tipologia compatibili con quanto indicato in jobs.py e utils.py
indicare i dati di schedulazione del job
visualizzare i dati di log relativi alle singole esecuzioni del job